HashMap 是 Java 面试中高频出现的题目,能有效考察候选人对数据结构和工程实现的理解。这篇文章梳理其核心设计思路与实现细节。
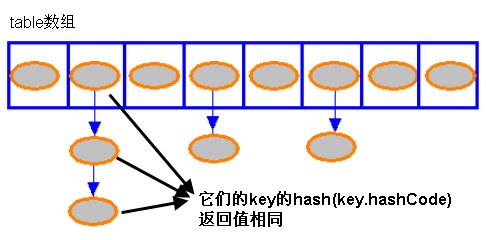
存储结构
HashMap 底层是一个 table 数组,数组中每个元素是一个 Node<K,V>(JDK 7 中名为 HashMapEntry)。当 put 一个键值对时,先计算 key 的 hashCode,再通过 hash & (table.length - 1) 定位到数组下标。如果多个 key 的哈希值落到同一个下标(哈希碰撞),则以链表形式挂载在该位置。
| |
上述代码来自 Android AOSP 对 JDK 7 HashMap 的实现。核心逻辑很清晰:遍历链表查找已有 key,找到则覆盖值,未找到则新增节点。
哈希函数
key.hashCode() 的结果还要经过一次扰动计算,目的是让高位信息也能参与低位索引的计算,降低碰撞概率。
Android AOSP / JDK 7 实现
采用多次异或移位进行扰动:
| |
JDK 8 实现
简化成一次扰动:(h = key.hashCode()) ^ (h >>> 16)。原因是红黑树的引入降低了链表的查找开销,不再需要复杂的扰动函数。
| |
下标计算:hash & (length - 1)
HashMap 的数组长度始终是 2 的 n 次方,这是有意为之的设计。length - 1 的二进制全是低位 1,hash & (length - 1) 等价于 hash % length,但位运算比取模快得多,且结果始终落在 [0, length-1] 范围内。
h & (length - 1) 示例(length=16,即 n-1 = 1111):
| hash (二进制) | & | length-1 (1111) | = | 结果 |
|---|---|---|---|---|
| 8 (0100) | & | 15 (1111) | = | 0100 (8) |
| 9 (0101) | & | 15 (1111) | = | 0101 (9) |
| 16 (10000) | & | 15 (1111) | = | 0000 (0) |
| 17 (10001) | & | 15 (1111) | = | 0001 (1) |
如果 length 不是 2 的幂(如 15),length - 1 是 1110,最后一位始终为 0,导致奇数下标永远不被使用,浪费空间且增加碰撞。
扩容机制
触发条件
当元素个数超过 capacity * loadFactor 时触发扩容。默认 loadFactor = 0.75,默认容量 16,首个阈值是 16 * 0.75 = 12。
为什么负载因子选 0.75?这是时间与空间的权衡。负载因子越大(如 1.0),空间利用率高但碰撞概率大,查找效率低;负载因子越小(如 0.5),查找快但浪费空间。0.75 是 JDK 经过长期测试选取的折中值。
扩容过程
容量翻倍(2 * 16 = 32),然后重新计算每个元素在新数组中的位置。这个 rehash 操作是 HashMap 中开销最大的地方。
JDK 7 在 rehash 时采用头插法(transfer() 方法),并发场景下容易形成环形链表导致死循环。JDK 8 改为尾插法,解决了这一问题。
预分配建议
如果已知要存放 1000 个元素,new HashMap(1000) 会将容量设为 1024(最近的 2 的幂)。但阈值 1024 * 0.75 = 768 < 1000,所以会在插入过程中触发扩容。更合理的是 new HashMap(2048),使 capacity * 0.75 > 1000,避免 resize。
JDK 8+ 的主要改进
JDK 8 对 HashMap 做了重大重构,核心变化如下:
| 改进项 | JDK 7 | JDK 8 |
|---|---|---|
| 节点命名 | HashMapEntry | Node,另有 TreeNode 子类 |
| 碰撞处理 | 仅链表(O(n)) | 链表 + 红黑树(O(log n)) |
| 树化阈值 | 无 | TREEIFY_THRESHOLD = 8 |
| 哈希函数 | 4 次扰动 | 1 次扰动 |
| 插入方式 | 头插法 | 尾插法 |
| 初始化时机 | 构造时分配数组 | 首次 put 时懒加载 |
红黑树转换条件
当链表长度超过 TREEIFY_THRESHOLD = 8 且 数组长度超过 MIN_TREEIFY_CAPACITY = 64 时,链表转为红黑树,最差查找从 O(n) 降到 O(log n)。如果数组长度不足 64,即使链表很长也先进行扩容而非树化。
树化阈值选 8 的原因:在理想随机哈希码且负载因子 0.75 的情况下,桶中节点数量服从泊松分布,链表长度达到 8 的概率约为 0.00000006(千万分之六),因此 8 是一个足够保守的阈值。
为什么降级阈值是 6
UNTREEIFY_THRESHOLD = 6,与树化阈值 8 保留 2 的缓冲区间,避免节点在阈值附近震荡时频繁转换。
线程安全问题
HashMap 不是线程安全的。并发 put 可能导致环形链表(JDK 7 的头插法在 rehash 时触发)、数据丢失等问题。多线程场景应使用:
ConcurrentHashMap:分段锁(JDK 7)或 CAS + synchronized(JDK 8)Collections.synchronizedMap():简单包装,性能较低HashTable:全表锁,已不推荐