Java HashMap的实现原理
昨天在群里讨论的时候,有人突然说HashMap的实现做面试题考新人一考一个准,一下子就能区分开是不是真的有工作经验.妈蛋,我竟然也不是很确认,特此总结一下:
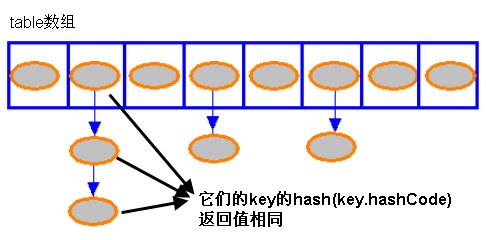
对于HashMap来说,你的每一次put操作后,都会对key取一次hashcode放入table中.table的每一个位置是一个HashMapEntry,因为key的hashcode有可能相同,这时table同一个位置的HashMapEntry就会next中追加一个HashMapEntry.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
@Override public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
void addNewEntry(K key, V value, int hash, int index) {
table[index] = new HashMapEntry<K, V>(key, value, hash, table[index]);
}
计算 Hash 码的方法:hash(),这个方法是一个纯粹的数学计算,其方法如下:
1
2
3
int hash = key.hashCode();
hash ^= (hash >>> 20) ^ (hash >>> 12);
hash ^= (hash >>> 7) ^ (hash >>> 4);
存值或者取值的时候,也是通过key的hash的方式去取,它总是通过h &(table.length -1)来得到该对象的保存位置——而 HashMap 底层数组的长度总是2的n次方,这一点可参看后面关于HashMap构造器的介绍。当length总是2的倍数时,h & (length-1)将是一个非常巧妙的设计:假设h=5,length=16, 那么h & length - 1将得到5;如果h=6,length=16, 那么h & length - 1将得到6……如果h=15,length=16, 那么h & length - 1将得到 15;但是当h=16时,length=16时,那么h & length - 1将得到0了;当h=17时,length=16时,那么h & length - 1将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内。
| h&(table.length-1) | hash | table.length-1 | result | ||
| 8&(15-1) | 0100 | & | 1110 | = | 0100 |
| 9&(15-1) | 0101 | & | 1110 | = | 0100 |
| 8&(16-1) | 0100 | & | 1111 | = | 0100 |
| 9&(16-1) | 0101 | & | 1111 | = | 0101 |
1
2
3
4
static int indexFor(int h, int length) {
//android 的实现是直接使用h & (length-1),无此方法
return h & (length-1);
}
当hashmap中的元素越来越多的时候,碰撞的几率也就越来越高(因为数组的长度是固定的),所以为了提高查询的效率,就要对hashmap的数组进行扩容,数组扩容这个操作也会出现在ArrayList中,所以这是一个通用的操作,很多人对它的性能表示过怀疑,不过想想我们的“均摊”原理,就释然了,而在hashmap数组扩容之后,最消耗性能的点就出现了:原数组中的数据必须重新计算其在新数组中的位置,并放进去,这就是resize。那么hashmap什么时候进行扩容呢?当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32,即扩大一倍,然后重新计算每个元素在数组中的位置,而这是一个非常消耗性能的操作,所以如果我们已经预知hashmap中元素的个数,那么预设元素的个数能够有效的提高hashmap的性能。比如说,我们有1000个元素new HashMap(1000), 但是理论上来讲new HashMap(1024)更合适,不过上面angeyu已经说过,即使是1000,hashmap也自动会将其设置为1024。 但是new HashMap(1024)还不是更合适的,因为0.75*1000 < 1000, 也就是说为了让0.75 * size > 1000, 我们必须这样new HashMap(2048)才最合适,既考虑了&的问题,也避免了resize的问题。