HashMap is one of the most frequently asked topics in Java interviews — it effectively tests a candidate’s understanding of data structures and engineering trade-offs. This article breaks down its core design and implementation details.
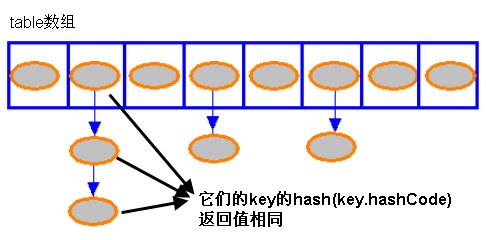
Storage Structure
HashMap is backed by a table array, where each element is a Node<K,V> (called HashMapEntry in JDK 7). When put is called, the key’s hashCode is computed and mapped to an array index via hash & (table.length - 1). If multiple keys hash to the same index (hash collision), entries are stored as a linked list at that bucket.
| |
The code above is from Android AOSP’s implementation of JDK 7 HashMap. The logic is straightforward: traverse the linked list looking for an existing key — overwrite on match, or append a new node.
Hash Function
The raw key.hashCode() goes through an additional perturbation to mix higher bits into the lower bits, reducing collision probability.
Android AOSP / JDK 7 Implementation
Multiple XOR-shift operations:
| |
JDK 8 Implementation
Simplified to a single XOR: (h = key.hashCode()) ^ (h >>> 16). The red-black tree addition in JDK 8 reduces linked-list lookup cost, so the simpler hash function suffices.
| |
Index Calculation: hash & (length - 1)
The array length is always a power of 2 by design. length - 1 in binary is all low-bit 1s, making hash & (length - 1) equivalent to hash % length — but bitwise AND is much faster than modulo, and the result always falls in [0, length-1].
h & (length - 1) example (length=16, so n-1 = 1111):
| hash (binary) | & | length-1 (1111) | = | Result |
|---|---|---|---|---|
| 8 (0100) | & | 15 (1111) | = | 0100 (8) |
| 9 (0101) | & | 15 (1111) | = | 0101 (9) |
| 16 (10000) | & | 15 (1111) | = | 0000 (0) |
| 17 (10001) | & | 15 (1111) | = | 0001 (1) |
If length is not a power of 2 (e.g., 15), length - 1 is 1110. The last bit is always 0, making odd indices never used — wasting space and increasing collisions.
Resizing
Trigger Condition
Resizing triggers when the number of elements exceeds capacity * loadFactor. Default loadFactor = 0.75, default capacity 16, so the first threshold is 16 * 0.75 = 12.
Why 0.75? It is a time-space trade-off. A higher load factor (e.g., 1.0) uses space efficiently but increases collisions and lookup cost. A lower factor (e.g., 0.5) speeds lookups but wastes memory. 0.75 is JDK’s empirically chosen sweet spot.
Resize Process
The capacity doubles (e.g., 2 * 16 = 32), and each entry’s index is recomputed. This rehash is the single most expensive operation in HashMap.
JDK 7 used head insertion during rehash (in transfer()), which can create circular linked lists under concurrent access — leading to infinite loops. JDK 8 switched to tail insertion, fixing this issue.
Pre-allocation Advice
If you plan to store 1000 entries, new HashMap(1000) sets capacity to 1024 (nearest power of 2). But 1024 * 0.75 = 768 < 1000, so a resize will still occur. The better choice is new HashMap(2048), ensuring capacity * 0.75 > 1000.
JDK 8+ Key Improvements
JDK 8 brought major changes:
| Feature | JDK 7 | JDK 8 |
|---|---|---|
| Entry name | HashMapEntry | Node + TreeNode subclass |
| Collision handling | Linked list only (O(n)) | Linked list + Red-black tree (O(log n)) |
| Treeify threshold | N/A | TREEIFY_THRESHOLD = 8 |
| Hash function | 4 perturbations | 1 perturbation |
| Insertion strategy | Head insertion | Tail insertion |
| Initialization | Array allocated at construction | Lazy: allocated on first put |
Red-Black Tree Conversion
When a linked list exceeds TREEIFY_THRESHOLD = 8 and the array length is at least MIN_TREEIFY_CAPACITY = 64, the list is converted to a red-black tree, improving worst-case lookup from O(n) to O(log n). If the array length is below 64, HashMap resizes first instead of treeifying.
The threshold of 8 is based on the Poisson distribution: under random hash codes and a 0.75 load factor, the probability of a bucket reaching 8 entries is approximately 0.00000006 — so 8 is a sufficiently conservative choice.
Why Untreeify Threshold Is 6
UNTREEIFY_THRESHOLD = 6 leaves a buffer of 2 between treeify and untreeify thresholds, preventing frequent conversions when the count oscillates near the boundary.
Thread Safety
HashMap is not thread-safe. Concurrent writes can cause circular linked lists (JDK 7’s head insertion during rehash), lost updates, and infinite loops. For concurrent access, use:
ConcurrentHashMap: segmented locks (JDK 7) or CAS + synchronized (JDK 8)Collections.synchronizedMap(): simple wrapper, lower throughputHashTable: table-wide lock, not recommended